Imagine that you go to your usual coffee place and encounter a gigantic queue. Going a little further, you realize that each individual has to wait in line until the coffee is prepared and handed over to them, as opposed to just placing the order at the counter and moving on. The latter approach seems pretty obvious since we know that order placement and the subsequent preparation process can be done as distinct, independent activities. The orders can be listed on a board and the barista can prepare them one after another. This idea is called asynchronous communication, where entities do not necessarily wait for each other to complete a task before initiating another.
This problem is not so uncommon in software systems either. For example, when you post a picture of your cat wearing Santa’s costume, other people don’t need to receive a notification about the same immediately (no matter how cute the cat looks). Otherwise, you could find yourself in a situation where the app is loading for hours because a lot notifications are still pending to be sent. The ‘notification service’ can do its job at its own pace; it just needs to receive the ‘message’ to do so from the ‘upload service’. (Services are basically software components that are responsible for carrying out certain tasks).
Now let’s see how we can establish the asynchronous communication between them.
Message queues in software systems
We realized that similar to how there was a board in the coffee shop where all the orders were listed, we require a data structure that would store the messages from the upload service so that the notification service can obtain and process them. Since these messages are to be processed one by one as they arrive, let’s store them in a Queue.
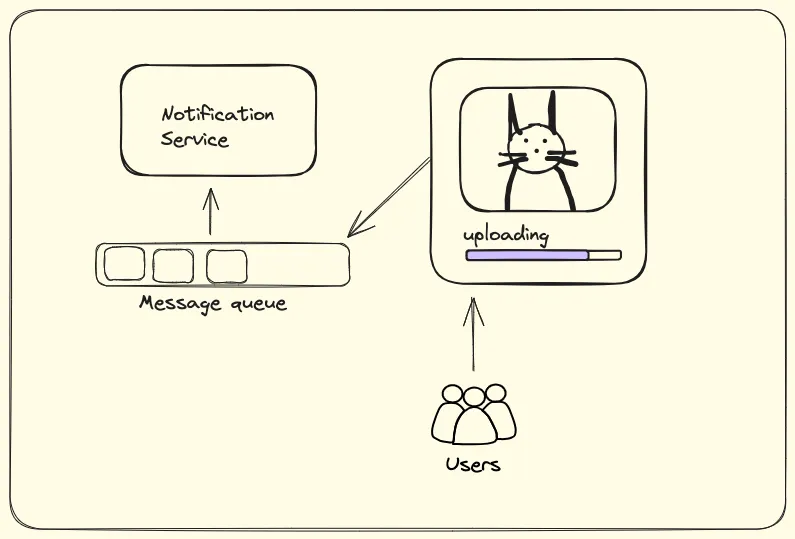
In this scenario, the upload service is called a Publisher, and the notification service is called Subscriber which has subscribed to the message queue. This type of model is called the Pub-sub model.
Limitations of Queues and the idea of multiple producers and subscribers
Perfect, we now have one service giving out messages and one service listening to those messages. Now let’s say we want to incorporate another service — an ‘analytics service’ that also wants to use these messages to find out how many of these uploads are done by teenagers. Can this service listen to the same queue to which the notification service is listening?
Well, theoretically it can. However, the queue is a transient data structure. meaning that the items pushed into the queue have to be popped out. More specifically, these messages will be popped out once they are processed or consumed. Thus, there’s a fair chance that one of the services might miss out on messages.
Event logs to the rescue
What we need here is something that’ll store these messages perpetually (at least for a configured amount of time). The appropriate data structure would be something like a “Log”. We know that a log is an append-only data structure. Therefore, multiple services can consume messages from this log at their own pace and no message would get lost.
Since these messages are not intended for a particular service, but rather something that any relevant service can consume, we will call them “Events”. Finally uploading a picture is an Event! (The cat finally got justice)
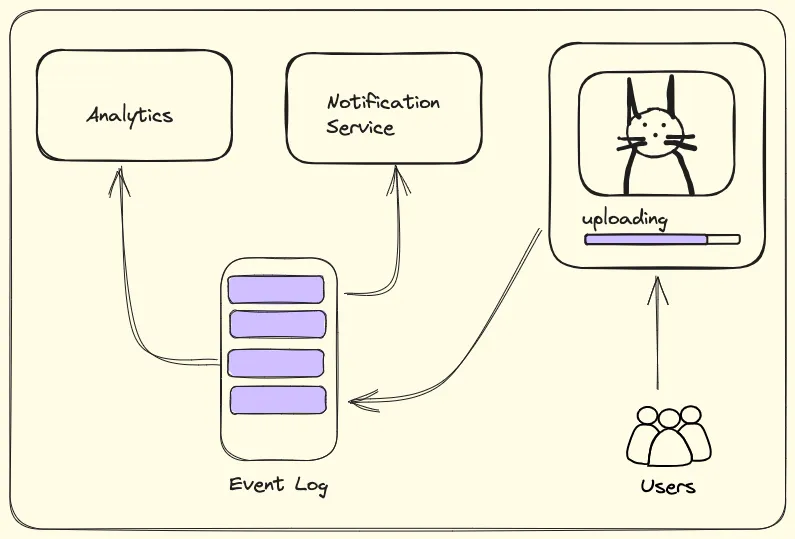
Coming to the Topic…
As our application becomes more complex, we’ll have multiple services interacting with each other and producing events. Not all events will be relevant for a particular service. This is why we logically segregate these events into separate Topics. Each service can now listen to the topics that are relevant to it.
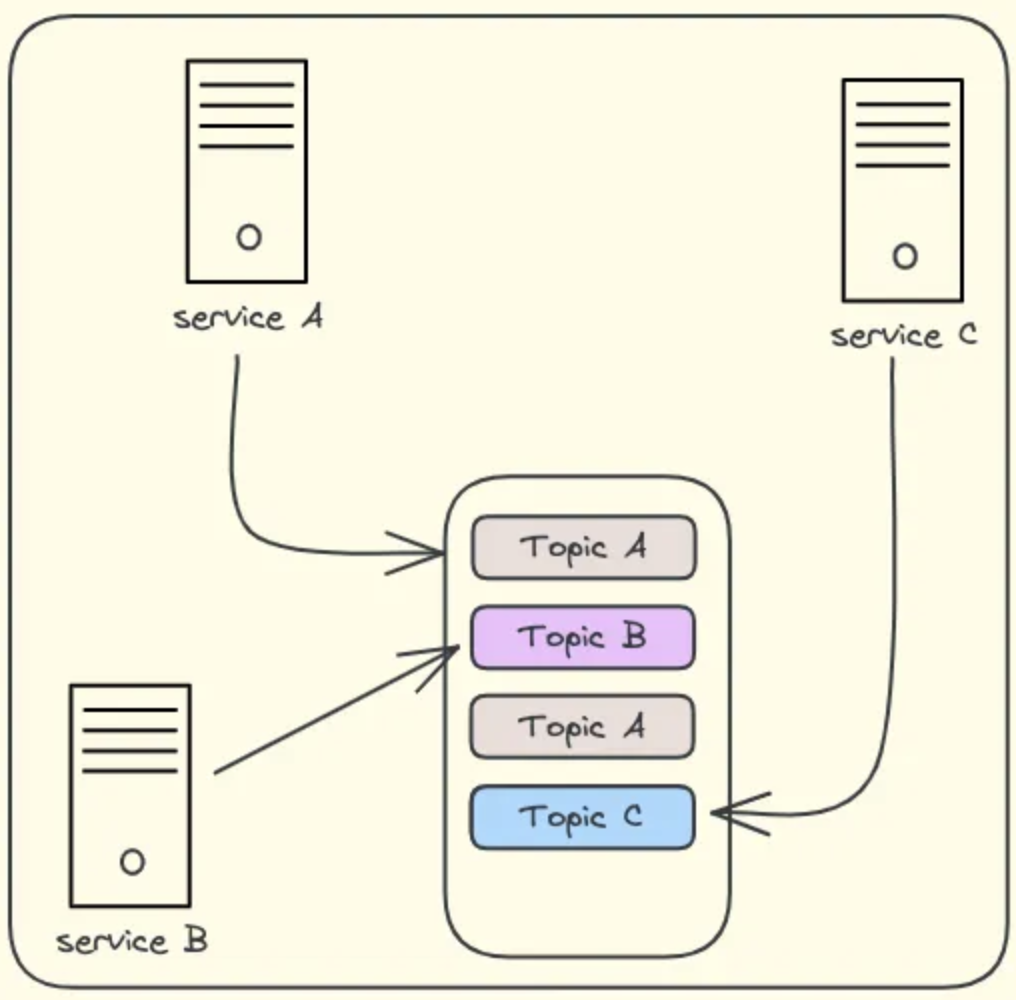
Handling the traffic…
Everything looks good until here, mainly because we have been dealing with just one server doing all the event logging. As the traffic to our application increases, the volume of generated events also increases. To handle this increasing load, we have to scale up our event-driven architecture. One possible way is to increase the capacity of our machine to handle more load. But at some point, even that will fall short, and there comes a limit to how much you can increase the capacity. So the obvious choice that comes to mind is adding more servers and making them all work together as a cluster. In other words, making it distributed!
How do we store logs in a distributed way?
Now that we have multiple nodes working together, we have to find a way to store this log on these servers. One option could be distributing topics among the nodes. This would work well until the topic sizes vary drastically. It’ll fail when the topic is too large to be stored on a single machine. We have to distribute these topics evenly to all the nodes in our cluster. The way we do that is by dividing these topics into multiple partitions.
Partitioning
Now, each node will have small partitions of all the topics. Just to make this system function properly even when one of the servers in the cluster is down (to make it fault-tolerant), we can also create multiple copies of the same partition and store them across the nodes. This way, if one node fails, the rest of the nodes will have the necessary event data. This is how our system will somewhat look like -
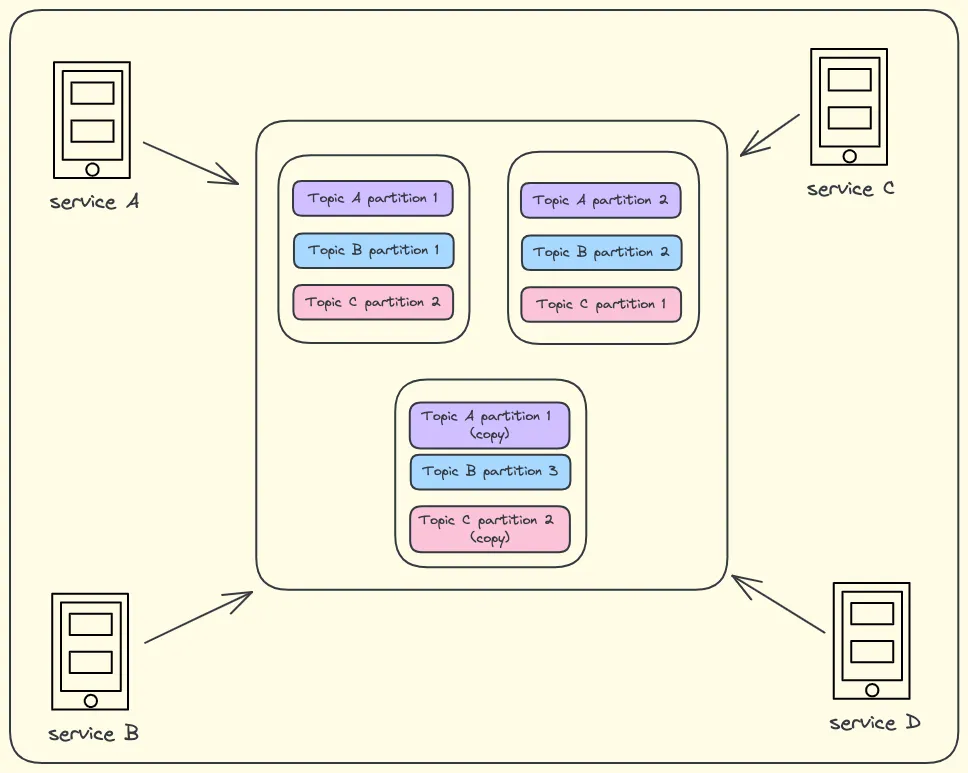
Whenever an event is published into the system, the publishing services can decide which partition it should go to by mentioning the partition ID. If it’s not mentioned, then the events will get distributed among the partitions in a round-robin manner.
Remembering progress with offsets
In order to make sure that the events are consumed in the right order, and no event is consumed multiple times or even skipped altogether, It’s important to keep track of the progress of a consumer in reading events from a topic. The way we do it is by using offsets.
When a consumer reads messages from a topic, it consumes them in order and advances its offset to keep track of the last successfully processed event. Consumers can specify the offset from which they want to start consuming messages. This flexibility allows consumers to resume processing from a specific point.
Putting it all together…
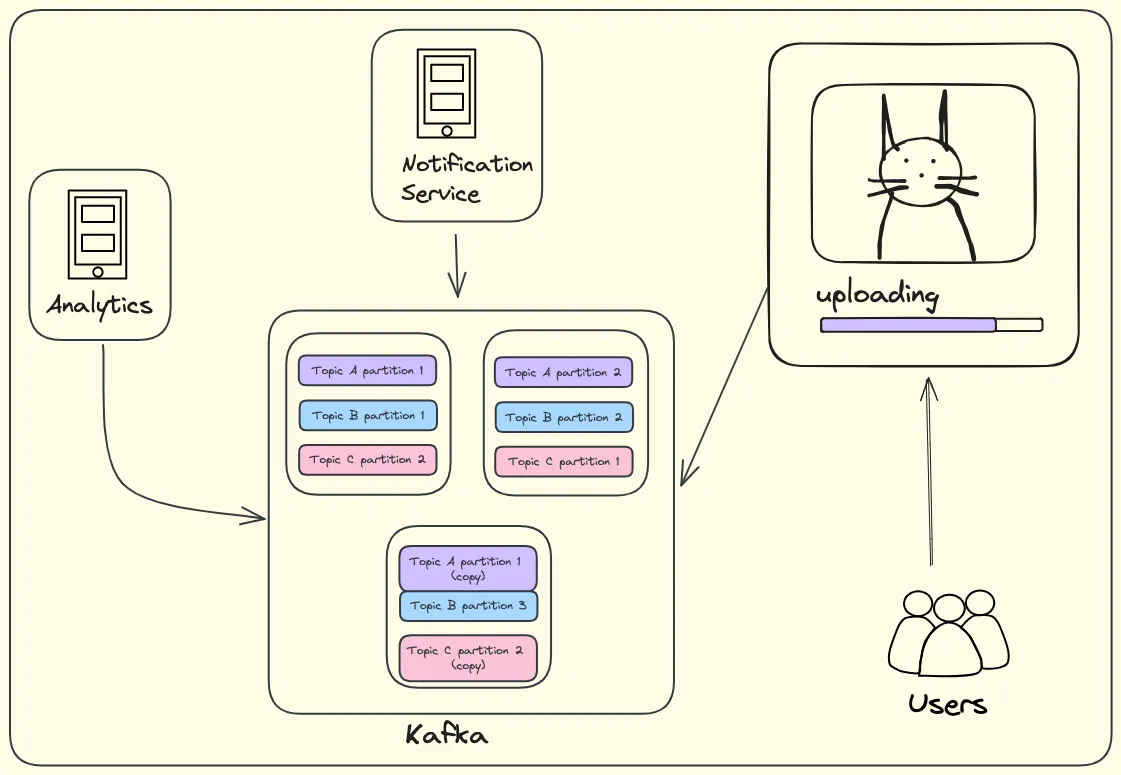
We now have our basic distributed event-driven architecture in place. The system that we built here to handle all the event processing is nothing but Apache Kafka, developed by Jay Kreps, Neha Narkhede, and Jun Rao at LinkedIn. The project was later open-sourced in 2011 and became part of the Apache Software Foundation. It has since gained widespread adoption in various industries for building scalable and reliable real-time data streaming platforms.
In today’s highly complex distributed systems, Kafka serves as the backbone, gracefully processing an endless stream of real-time data. It’s one of the most well-engineered innovations in the world of modern computing with a wide spectrum of applications. While this was just an overview of it, there’s still a lot to talk about Apache Kafka.
I hope reading this article was ‘eventful’ for you!